字孿生優(yōu)锘科技")
字孿生優(yōu)锘科技")












白話知識(shí)圖譜及其在CMDB中的應(yīng)用
 2020-10-10
2020-10-10  by
by CMDB一直是運(yùn)維建設(shè)的重點(diǎn)和難點(diǎn)。前段時(shí)間和北大同學(xué)一起探討有無(wú)可能利用知識(shí)圖譜相關(guān)的技術(shù)和方法重構(gòu)CMDB?沒(méi)想到經(jīng)過(guò)短短半年時(shí)間,北大同學(xué)就在這方面取得了重大進(jìn)展,現(xiàn)已完成算法驗(yàn)證,并發(fā)表國(guó)際學(xué)術(shù)論文《Mining Configuration Items From System Logs through Distant Supervision》。
由于學(xué)術(shù)論文比較晦澀難懂,所以我盡可能用樸實(shí)的文字將我們的工作成果和思考總結(jié)給大家做一個(gè)簡(jiǎn)要匯報(bào),歡迎批評(píng)指正。
本文主要包含兩塊內(nèi)容:1、對(duì)知識(shí)圖譜的基本概念和思想起源做一個(gè)簡(jiǎn)單的介紹;2、知識(shí)圖譜對(duì)CMDB的啟發(fā)以及我們的實(shí)踐成果。閱讀時(shí)間約20分鐘。
1. 什么是知識(shí)圖譜
你可以沒(méi)聽(tīng)過(guò)知識(shí)圖譜,但一定聽(tīng)過(guò)人工智能。人工智能可以簡(jiǎn)單的分為兩大類(lèi):感知智能和認(rèn)知智能。感知智能即視覺(jué)、聽(tīng)覺(jué)、觸覺(jué)的感知能力。比如,自動(dòng)駕駛汽車(chē),就是通過(guò)激光雷達(dá)等感知設(shè)備和人工智能算法來(lái)實(shí)現(xiàn)感知智能的。比感知智能更厲害的是認(rèn)知智能。認(rèn)知智能通俗講是讓機(jī)器能理解會(huì)思考,能夠知識(shí)推理、因果分析等等。而知識(shí)圖譜,就是實(shí)現(xiàn)認(rèn)知智能的基礎(chǔ)技術(shù)。
那么,知識(shí)圖譜究竟是什么呢?
別急,我們先看兩個(gè)典型的知識(shí)圖譜的應(yīng)用場(chǎng)景。
第一個(gè)場(chǎng)景是智能搜索。Google于2012年在搜索引擎中引入知識(shí)圖譜技術(shù),嘗試讓機(jī)器理解了人們輸入的搜索關(guān)鍵字是什么意思,有什么意圖,以便給出更加準(zhǔn)確、豐富的搜索結(jié)果。
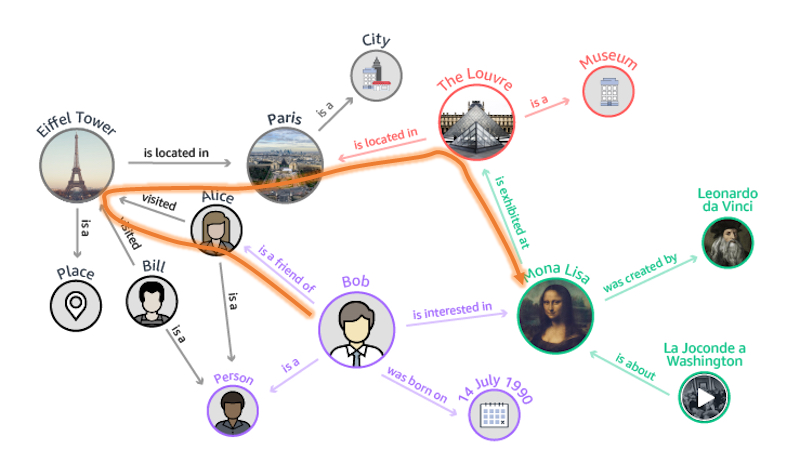
另一個(gè)場(chǎng)景是智能問(wèn)答。比如,互聯(lián)網(wǎng)或知識(shí)庫(kù)中可能記錄了大量碎片化的信息和知識(shí):

Bob想去看《蒙娜麗莎》,他很想知道自己有沒(méi)有朋友可能去看過(guò)?傳統(tǒng)的知識(shí)庫(kù)很難直接告訴你答案。但是如果將上面片段信息轉(zhuǎn)化成知識(shí)圖譜,就能讓電腦理解這些信息的關(guān)系,進(jìn)而能直接給出答案:Bob的朋友Alice很可能去Louvre看了《蒙娜麗莎》。
上面兩個(gè)場(chǎng)景讓我們對(duì)知識(shí)圖譜有了感性認(rèn)識(shí),可知識(shí)圖譜是從哪兒來(lái)的呢?
2. 知識(shí)圖譜的思想起源
如果要探究知識(shí)圖譜的思想起源,則應(yīng)將時(shí)間上溯到1922年英國(guó)哲學(xué)家維特根斯坦和他的《邏輯哲學(xué)論》。

在這本著作中,維特根斯坦主張世界的本質(zhì)就是語(yǔ)言。因?yàn)檎Z(yǔ)言是人類(lèi)思想的表達(dá),是整個(gè)文明的基礎(chǔ),所以語(yǔ)言和世界是一體的。他從報(bào)紙上車(chē)禍的示意圖中領(lǐng)悟到,任何有意義的語(yǔ)句都應(yīng)該能表達(dá)成由“實(shí)體和關(guān)系”組成的圖譜,而語(yǔ)句不斷積累疊加形成的巨大圖譜就是整個(gè)世界。
這一思想對(duì)哲學(xué)乃至數(shù)理邏輯都產(chǎn)生了劃時(shí)代的影響,為知識(shí)圖譜技術(shù)奠定了深刻而牢固的思想基因,揭示了知識(shí)圖譜的本質(zhì),即:用對(duì)象及其關(guān)系的語(yǔ)言符號(hào)來(lái)描述的現(xiàn)實(shí)世界的圖譜。
3. IT運(yùn)維領(lǐng)域的知識(shí)圖譜
既然語(yǔ)言在現(xiàn)實(shí)世界如此重要。那么在IT的世界,機(jī)器之間又是用什么語(yǔ)言來(lái)交流呢?是日志。
日志是IT系統(tǒng)和設(shè)備在運(yùn)行過(guò)程中自產(chǎn)生的數(shù)據(jù),所以也稱(chēng)為機(jī)器數(shù)據(jù)(Machine Data)。日志的信息量非常豐富,我們可以從日志中得知系統(tǒng)正在進(jìn)行什么處理操作(系統(tǒng)日志),正在受理和發(fā)起哪些訪問(wèn)請(qǐng)求(訪問(wèn)日志),是否出現(xiàn)了異常狀況(錯(cuò)誤日志)等等。但由于日志都是半結(jié)構(gòu)性數(shù)據(jù),中英文混合、結(jié)構(gòu)復(fù)雜、內(nèi)容多樣,在理解上較為困難,所以并沒(méi)有被有效利用,人們一般在排查故障時(shí)才會(huì)查看日志。
能否將這些機(jī)器語(yǔ)言轉(zhuǎn)換成IT運(yùn)維的知識(shí)圖譜,從而實(shí)現(xiàn)類(lèi)似智能根因分析和影響分析呢?比如,當(dāng)要對(duì)某臺(tái)服務(wù)器做重啟時(shí),知識(shí)圖譜就能告訴我們這臺(tái)服務(wù)器上現(xiàn)在正在運(yùn)行哪些定時(shí)作業(yè)、這些作業(yè)又會(huì)影響哪些下游作業(yè),這些下游作業(yè)屬于什么應(yīng)用系統(tǒng),這些應(yīng)用系統(tǒng)是給哪些業(yè)務(wù)提供服務(wù)的。
咦,這不是CMDB在干的事兒嘛?沒(méi)錯(cuò),其實(shí)CMDB的本質(zhì)就是IT運(yùn)維領(lǐng)域的知識(shí)圖譜。而知識(shí)圖譜相關(guān)技術(shù),也的確能夠幫助CMDB提升數(shù)據(jù)質(zhì)量和使用體驗(yàn)。當(dāng)然本文主要探討第一個(gè)問(wèn)題,因?yàn)镃MDB最頭痛的還是數(shù)據(jù)質(zhì)量。至于第二個(gè)問(wèn)題以后會(huì)專(zhuān)門(mén)撰文闡述。
在探討第一個(gè)問(wèn)題前,我們先簡(jiǎn)單回顧一下傳統(tǒng)CMDB是如何構(gòu)建的。
傳統(tǒng)構(gòu)建CMDB的方式經(jīng)歷了三個(gè)階段:
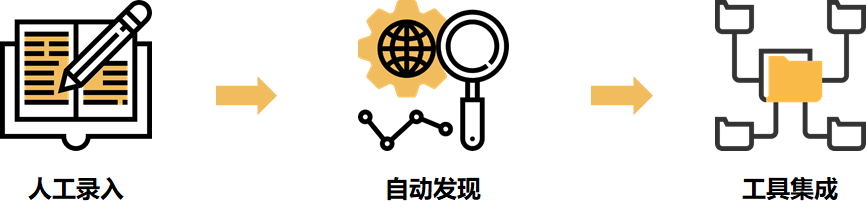
最早期是人工錄入,但工作量太大,且容易不準(zhǔn),因此很早就被廢棄。后來(lái)采用自動(dòng)發(fā)現(xiàn)手段,通過(guò)命令從機(jī)器上采集配置數(shù)據(jù),這種方法有一定成效,但也存在安全隱患、性能影響及可用性方面的風(fēng)險(xiǎn),所以真正實(shí)踐起來(lái)困難重重。后來(lái)隨著自動(dòng)化、云計(jì)算技術(shù)的發(fā)展,人們發(fā)現(xiàn)大部分配置數(shù)據(jù)根本不需要采集,直接從自動(dòng)化、網(wǎng)管、云管等平臺(tái)中獲取即可。這種做法規(guī)避了自動(dòng)發(fā)現(xiàn)帶來(lái)的安全隱患和性能風(fēng)險(xiǎn),但也有局限性,就是CMDB的數(shù)據(jù)完全依賴這些第三方數(shù)據(jù)源,如果這些數(shù)據(jù)源不靠譜(比如覆蓋率或完整性不行,或壓根沒(méi)有接口供數(shù))CMDB就歇菜了。而且大量數(shù)據(jù)接口的開(kāi)發(fā)和維護(hù)也是頭痛的問(wèn)題。
有沒(méi)有一種新的方法:讓維護(hù)配置數(shù)據(jù)的工作量更小、風(fēng)險(xiǎn)更低、覆蓋面更廣、泛化能力更強(qiáng)呢?
這就要靠知識(shí)圖譜了。我們認(rèn)為,隨著日志數(shù)據(jù)的不斷細(xì)化、大數(shù)據(jù)存儲(chǔ)和處理能力的提升以及機(jī)器學(xué)習(xí)技術(shù)的日益發(fā)展,讓機(jī)器從海量日志中自動(dòng)甄別和提取配置數(shù)據(jù)的條件正在逐漸成熟。因此,優(yōu)锘科技正在與北大師生密切合作,將最新的算法和研究成果應(yīng)用到CMDB中。
下面我將以網(wǎng)絡(luò)告警日志為例闡述我們的實(shí)現(xiàn)方法,首先來(lái)看一下整體流程:
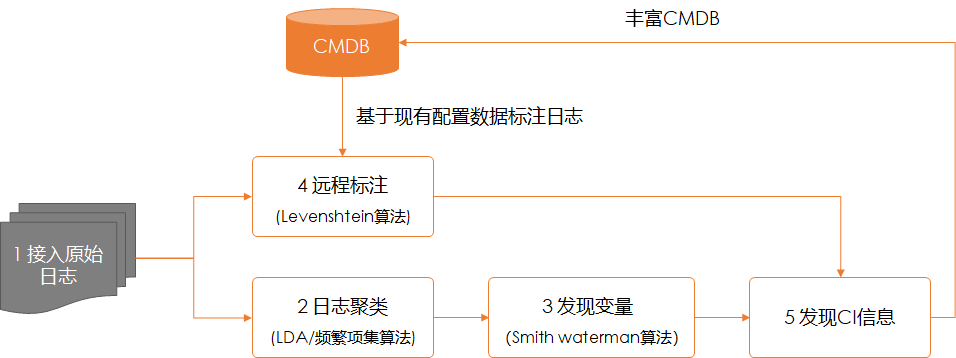
流程總體上分為五個(gè)步驟,下面會(huì)逐一說(shuō)明:
第一步:接入原始日志數(shù)據(jù)
本次實(shí)驗(yàn)共接入9萬(wàn)條網(wǎng)絡(luò)設(shè)備syslog數(shù)據(jù)。
第二步:日志聚類(lèi)
所謂“物以類(lèi)聚、人以群分”,人們會(huì)按照其品行、愛(ài)好而形成團(tuán)體,這就是聚類(lèi)。日志也一樣,想要分析海量日志數(shù)據(jù),就要先對(duì)其聚類(lèi),從而搞清楚各種五花八門(mén)的日志背后是否有統(tǒng)一的模板。
最常用的聚類(lèi)算法叫“頻繁項(xiàng)集”。項(xiàng)集指數(shù)據(jù)的集合,而頻繁項(xiàng)集就是從概率統(tǒng)計(jì)維度,從一堆貌似無(wú)規(guī)則的數(shù)據(jù)中找到最頻繁符合某項(xiàng)特征規(guī)則的數(shù)據(jù)集合。我們經(jīng)常聽(tīng)說(shuō)的用戶消費(fèi)行為分析、啤酒和尿布的故事等等就是頻繁項(xiàng)集算法的應(yīng)用場(chǎng)景。只不過(guò)在日志場(chǎng)景下,聚類(lèi)的特征規(guī)則不是日志的發(fā)生時(shí)間和地點(diǎn),而是日志內(nèi)容的相似度。
起初我們也采用頻繁項(xiàng)集算法對(duì)日志聚類(lèi),但效果不好。因?yàn)樵撍惴ㄒ葘?duì)日志做“對(duì)齊匹配”(可簡(jiǎn)單理解為結(jié)構(gòu)化),然后才能進(jìn)行聚類(lèi)分析。可是原始日志是多語(yǔ)言混合結(jié)構(gòu)的,其內(nèi)容格式非常混亂且包含很多噪音,對(duì)全量日志做對(duì)齊匹配就會(huì)生成大量無(wú)效的日志模板。因此我們放棄了這個(gè)算法。
后來(lái)經(jīng)過(guò)大量實(shí)驗(yàn),我們發(fā)現(xiàn)LDA算法的效果比較好。LDA是一種基于主題模型的算法,它有三大優(yōu)勢(shì):
** 不需要對(duì)齊匹配;**
** 是基于語(yǔ)義挖掘的主題模型;**
** 是一種無(wú)監(jiān)督機(jī)器學(xué)習(xí)技術(shù)。**
第1項(xiàng)優(yōu)勢(shì)避免了在全局開(kāi)展無(wú)意義的對(duì)齊匹配所造成的大量無(wú)效日志模板。
第2項(xiàng)優(yōu)勢(shì)是針對(duì)傳統(tǒng)的文檔匹配算法而言的。傳統(tǒng)方法(如TF-IDF等)在匹配文檔相似度時(shí)不考慮文字背后的語(yǔ)義關(guān)聯(lián),僅通過(guò)查看兩個(gè)文檔共同出現(xiàn)的單詞的數(shù)量來(lái)判斷相似度,共同單詞越多就越相似。這就有問(wèn)題了,比如,“他們的CMDB很成功”和“他們的配置管理超牛”,這兩句話雖然共同的單詞很少,但它們的語(yǔ)義非常相似。如果按傳統(tǒng)的方法判斷這兩個(gè)句子肯定相似度低,而LDA就會(huì)考慮文字背后的語(yǔ)義,進(jìn)而給出高相似度結(jié)論。
第3項(xiàng)優(yōu)勢(shì)提到LDA是一種無(wú)監(jiān)督機(jī)器學(xué)習(xí)技術(shù)。什么是無(wú)監(jiān)督?簡(jiǎn)單的說(shuō)就是不需要做大量標(biāo)注它就能自己學(xué)。其實(shí)CMDB數(shù)據(jù)量就這么點(diǎn)兒,也沒(méi)法提供大量標(biāo)注。用圖像識(shí)別這類(lèi)監(jiān)督型機(jī)器學(xué)習(xí)技術(shù)完全不靠譜。
下面是我們用LDA算法的實(shí)驗(yàn)結(jié)果,將9萬(wàn)條日志聚合成了23個(gè)分類(lèi)(也可以理解為日志模板),正確率達(dá)到90%。比如下面四條日志都表達(dá)了control plane狀態(tài)異常這個(gè)主題,因此可歸為同一個(gè)日志模板。

第三步:識(shí)別變量
完成日志聚類(lèi)后,我們就能以日志模板為單元分析其中的日志是否包含CI數(shù)據(jù)。從經(jīng)驗(yàn)上看,CI數(shù)據(jù)一般來(lái)自日志中的變量,因?yàn)槿罩局械某A恳话愣荚诿枋霎?dāng)前正在干什么事兒,而變量一般描述誰(shuí)在干或在干誰(shuí),這里的“誰(shuí)”就是CI。所以,要識(shí)別潛在CI,就要先弄清楚哪些是變量。
但怎么從一大堆文本中識(shí)別變量呢?如果是人來(lái)做,肯定會(huì)逐條對(duì)比日志,如果發(fā)現(xiàn)它們?cè)谀硞€(gè)局部不一樣,那么這個(gè)局部就很可能是變量。類(lèi)似的方法讓機(jī)器做就是史密斯-沃特曼算法(Smith-Waterman algorithm)。它是一種對(duì)局部序列比對(duì)(注意不是全局比對(duì))的算法,最早用于基因序列比對(duì),用來(lái)找出兩個(gè)序列中具有高相似度的基因片段。嗯?為什么找相似片段?不是要找不一致的片段嗎?沒(méi)錯(cuò),我們的做法是先把相似片段找到,然后將其剔除,剩下的就是不相似的片段了。這種方法也不是我們先創(chuàng),它常常用來(lái)分析基因差異。舉個(gè)生活例子,鐘宏這幾年越來(lái)越禿,這是為什么呢?這肯定不是工作辛苦的原因,因?yàn)槲揖蜎](méi)禿啊。如果用史密斯-沃特曼算法比對(duì)一下我倆的基因,剔除掉相似片段,找到不一致的片段,也許就能發(fā)現(xiàn)他早年謝頂?shù)幕颉?/p>

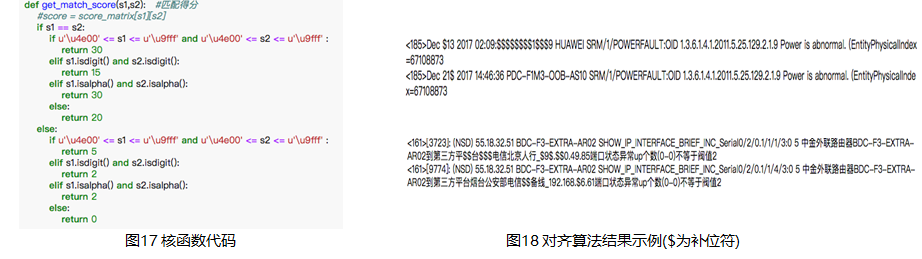
回到正題,由于原生的Smith-Waterman算法是針對(duì)基因序列比對(duì)的(原始核函數(shù)是G-T與A-C匹配則得分),而運(yùn)用到運(yùn)維日志比對(duì)上就需要額外定制核函數(shù),增加漢語(yǔ)字符的匹配權(quán)重。
經(jīng)過(guò)不斷的實(shí)驗(yàn)和調(diào)參,我們獲得了比較滿意的結(jié)果,識(shí)別出了每個(gè)日志模板中的變量,后來(lái)又剔除掉日期、序號(hào)等日志片段后,剩下的大概率都是變量了。
現(xiàn)在我們知道哪些日志片段是變量,也知道其中必有CI,如果是你會(huì)怎么做?
你肯定會(huì)觀察這些變量值,然后去CMDB中核對(duì),看它們與哪些CI屬性類(lèi)似,進(jìn)而判斷這些變量就是對(duì)應(yīng)這些CI屬性。這項(xiàng)工作如果讓機(jī)器來(lái)做,就要用到遠(yuǎn)程標(biāo)注技術(shù)了。
第四步:遠(yuǎn)程標(biāo)注
遠(yuǎn)程標(biāo)注的目的,是讓機(jī)器能夠模擬人的行為,以CMDB數(shù)據(jù)做樣本,輔以機(jī)器學(xué)習(xí)算法,讓機(jī)器理解日志的語(yǔ)義,進(jìn)而從中提取出CI數(shù)據(jù)。
最簡(jiǎn)單的標(biāo)注方法是嚴(yán)格匹配,即,將CMDB中的CI屬性值與日志進(jìn)行嚴(yán)格匹配,能匹配的就給這段日志片段標(biāo)注相應(yīng)的CI屬性。但這種做法的效果并不好,因?yàn)镃MDB的數(shù)據(jù)并不完整,而且數(shù)據(jù)質(zhì)量不好,嚴(yán)格匹配根本匹配不出啥玩意來(lái)。為了提升泛化能力,我們采用了基于編輯距離的模糊匹配算法,即levenshtein算法。
所謂編輯距離是指由一個(gè)字串轉(zhuǎn)化成另一個(gè)字串最少的操作次數(shù),這里說(shuō)的操作包括包括插入、刪除、替換。次數(shù)越少,則編輯距離越短,字符串的相似度就越大。例如將eeba轉(zhuǎn)變成abac,需要經(jīng)過(guò)下面三次操作:
** eba(刪除第一個(gè)e)**
** aba(將剩下的e替換成a)**
** abac(在末尾插入c)**
所以eeba和abac的編輯距離就是3。
當(dāng)然,為了提升匹配效果,我們引入了伸縮控制機(jī)制,對(duì)于CMDB中的一個(gè)CI屬性中正教的CI屬性值x,按照其長(zhǎng)度m將日志(長(zhǎng)度為n)切分為n-m個(gè)子串yi;然后計(jì)算萊文斯坦比,即,levenshtein_ratio(x,yi),取最大x,設(shè)置閾值判定x是否與yi具有強(qiáng)相似性。實(shí)驗(yàn)中閾值設(shè)置為0.8(1表示完全相似,0表示完全不相似),也就是說(shuō)只要大于0.8,就證明CMDB中的某個(gè)CI屬性與該日志片段匹配上了。

完成遠(yuǎn)程標(biāo)注后,我們的工作就基本完成了,剩下的就是給機(jī)器喂大量的日志,然后坐等CMDB誕生就行了。不過(guò)有時(shí)候可能拉的不對(duì),所以還需要一定的人工調(diào)整和過(guò)濾。不過(guò)人工介入的操作也會(huì)反饋給機(jī)器持續(xù)優(yōu)化算法,所以理想情況下這種介入操作會(huì)越來(lái)越少。這種做法被稱(chēng)為hybrid intelligence - 混合智能。
下一篇,我們將闡述一個(gè)使用知識(shí)圖譜技術(shù)自動(dòng)構(gòu)建CMDB的案例。
文章分類(lèi)
熱門(mén)標(biāo)簽
熱門(mén)文章
 11.9K
11.9K


